NLP for all languages
You couldn’t understand all the world’s digital communications, even if you had access and time. Online communication continues to grow but English’s share is diminishing—so not only are we creating more unstructured data than ever, we are doing it in an unprecedented number of languages. Language technologies haven’t kept pace.
We exist in a thin sliver of time when the world has very quickly become connected, but we have few resources for the majority of the world’s languages. There are probably 5,000 languages spoken by people with access to a cellphone right now, but we know very little about most of them. It’s Endangered Languages Week this week, so this post tackles Natural Language Processing for less resourced languages.
One of the positive side-effects of globalization for smaller languages has been the ability for disparate communities to keep using their languages by phone or over the internet. The affordability of audio-recording equipment has also meant that languages that are only spoken, which are most of them, can be permanently recorded for the first time.
But Natural Language Processing is one area where technology has not kept up because it has typically been applied only to languages with a lot of data. So the majority of the world’s languages have never had their own search engines, spam filters, spelling checkers, or other language technologies. It would never be cost-effective for industry to provide a solution dedicated to every language—the number of potential users is simply too low. So rather than end up with relatively few services, endangered languages tend to end up with none, perpetuating the bias.
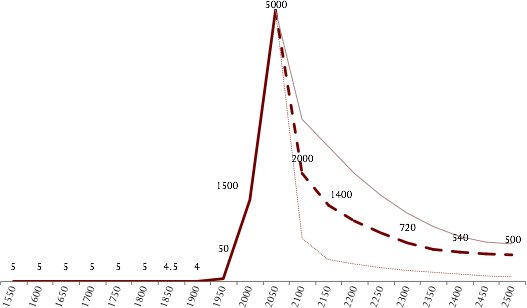
Figure 1: The average number of languages that a person could encounter on a given day, for the previous and following 500 years. Because of cellphones that number is now around 5,000. But with the rate of language-loss we are seeing, this will quickly drop. We will never again be so under-resourced to understand the people that we can reach.
Machine-learning for every language
One of our goals at Idibon is to produce language technologies that work in any language. So while endangered languages aren’t our core business, we can support tools that can be applied to endangered languages without disappearing with the end of a grant or research funds. That is, we want the existence of broadly applicable language technologies to be sustainable.
We saw exactly this recently with the Navajo language (Diné bizaad in the Navajo language). For one of our clients our system was able to automatically adapt to user behavior to perform content moderation in Diné bizaad, separating constructive from non-constructive comments from users who spoke the language. With 100,000+ speakers, Navajo is the most widely spoken language native to North America but is still considered threatened. By giving it equal status with several dozen other languages for this client, we were thrilled to see our machine-learning systems adapting to this language.
Greater-than-zero sum gain
Navajo enjoys a special history in our perception of the benefits of linguistic diversity. In the 1970s, studies found that bilingual English/Navajo children had better educational proficiency than their peers enrolled in English-only, for subjects including English itself. That is, children who were taught with a 75%:25%, English:Navajo ratio, spoke better English than those who were taught in 100% English.
This went against a decades-long policy of banning indigenous languages from US education (and elsewhere in the world) based on the assumption that teaching only in English would improve assimilation. In reality, we are wired to speak more than one language (it’s always been more common) and benefit from the diversity. These studies showed what many linguists have long known, and what much of the world still needs to learn: in order to best meet a globalized the world on their own terms, speakers of endangered languages tend to be better off maintaining their linguistics practices in complement with their newer languages.

Figure 2: Fieldwork: Idibon’s CEO, Robert Munro, recording the Matses language in the Peruvian Amazon in 2008.
Every digital language
Every language is equal in the digital world—it is a historical quirk that have made some like English and Chinese so dominant. Many years ago, I spent two years working as the first software developer for the Endangered Languages Archive, and I still draw on my experience designing systems to support so many languages, and later fieldwork recording the Matses language of the Amazon. I’m by no means the only person combining these backgrounds—it is surprisingly frequent. My co-founder, Tyler Schnoebelen, studied Shabo, a language isolate in Ethiopia. Our company advisor, Chris Manning, is probably the most well know researcher in statistical NLP and has also worked building dictionaries for endangered languages. The organizer of the Bay Area NLP Meetup Group, Stuart Robinson, has studied a number of languages in Papua New Guinea. Steven Bird, an author of Natural Language Processing with Python, has worked extensively documenting endangered languages. A number of researchers like Jason Baldridge and Alexis Palmer have looked at injecting machine-learning into the language documentation process. And just yesterday, I met Misfit Wearables’ founder Sonny Vu and found he studied linguistics at MIT under Ken Hale, retaining an impressive amount of knowledge of Navajo syntax.
One of the most positive aspects of what we are doing is that it can swing the bias back in favor of smaller languages. We can launch, test and iterate our tools in a handful of dominant languages, and then apply them to smaller languages already optimized and ready to be adapted with minimal extra effort. We look forward to supporting more endangered language speakers and communities as we grow, for the economic, scientific, cultural, and personal reasons to celebrate and support the diversity of the world’s languages.
– Rob Munro